How Ad Platforms Analyze Account Cluster Behavior, Not Individual Actions

There's one thing many teams only figure out after a string of inexplicable bans. Platforms stopped looking at accounts as isolated units a long time ago. What happens inside a single profile is just data. But how several accounts behave together — how they appear in the same environment, how their activity overlaps across time, geography and devices — that's the signal the machine learning systems at Meta, Google and TikTok are actually working with.
The problem is that most teams build their defenses at the individual account level. They rotate user-agents, clear cookies, swap IPs before each session. That made sense a few years back when detection models were simpler. Now it's not just insufficient — it actively creates an illusion of protection where none exists.
- What Actually Changed in Platform Logic
- How Platforms Build Cluster Profiles
- Why Clean Accounts No Longer Mean Safe Accounts
- Operational Consequences That Usually Get Misdiagnosed
- What Teams That Stay Stable Actually Do Differently
- Real Scenarios: What This Looks Like in Practice
- FAQ
- Instead of a Conclusion
What Actually Changed in Platform Logic
Anti-fraud systems used to react to specific triggers — a suspicious IP, an unusual device, a sudden spend spike. Now all of that has become just one input inside a much broader context. Meta and Google have accumulated enough data to build behavioral relationship graphs between accounts. TikTok followed the same path, and faster than most expected.
The point isn't that one account did something wrong. The point is that a group of accounts starts exhibiting cluster behavior — shared patterns that aren't typical of independent advertisers. Their sessions originate from the same subnet despite different proxies. They're created at intervals too uniform to be random. Their initial activity follows an identical script. Their creatives are structurally similar or overlap in audience targeting.
None of these signals means much in isolation. Together, they form a pattern stable enough for the platform to start treating the entire cluster as a single object.
And this is where things get particularly painful: when a platform makes a decision at the cluster level, it doesn't always ban everything at once. What typically begins is a gradual erosion — reach drops, bid caps tighten, ad approvals start failing. The team assumes the problem is with the creatives or the offer. They spend a week testing new combinations, rewriting copy, cycling through audiences — and nothing improves. Because the issue isn't the ad materials. The entire account group is already sitting under reduced trust.
How Platforms Build Cluster Profiles
It's not one signal or one data layer. The models work across multiple levels simultaneously.
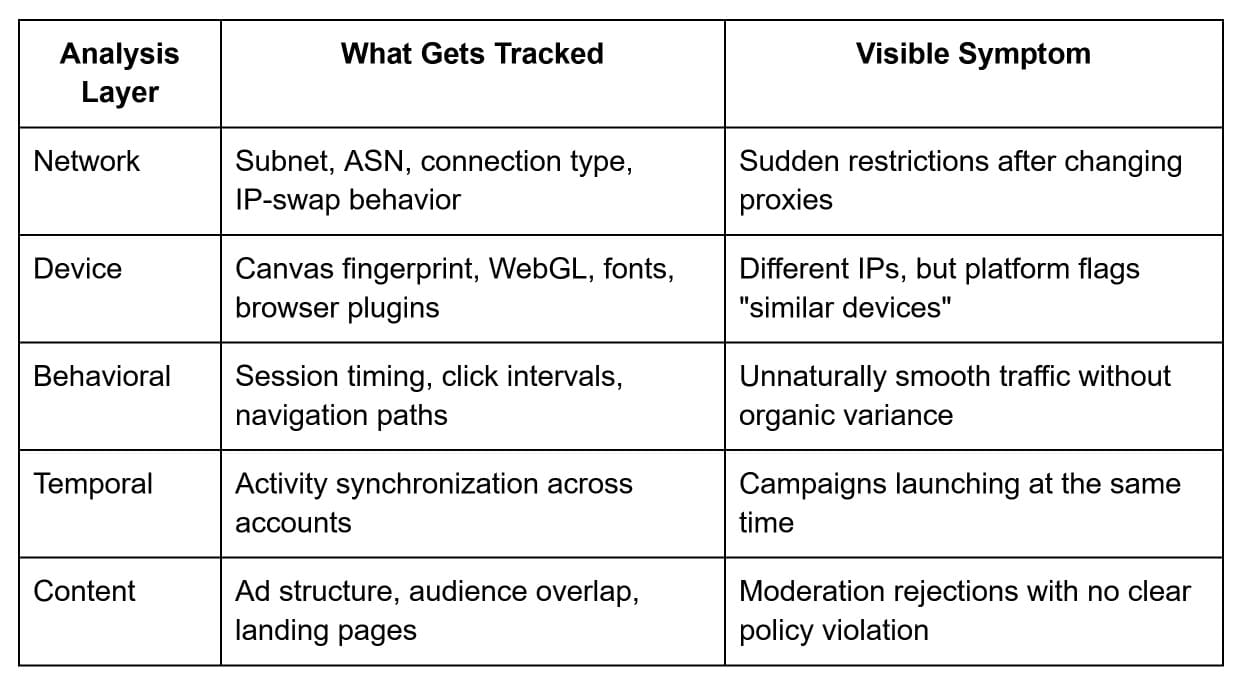
None of these layers is individually decisive. That's exactly why the standard bypass toolkit — VPN, basic proxy rotation, entry-level antidetect environments — gives a sense of control while doing nothing about the problem at the cluster analysis level.
What's actually happening inside these systems is hard to observe directly from the outside. But based on how accounts behave following specific actions, it's possible to draw reasonably precise conclusions about the logic platforms are applying.
Why Clean Accounts No Longer Mean Safe Accounts
This is probably the most counterintuitive part for most teams. They warm up accounts carefully. Build a real history, organic interactions, clean billing records. Everything by the book. Then an account that looks perfect in isolation turns out to be part of a low-trust cluster — simply because it was created and warmed up in the same environment as the others.
Here's the thing worth understanding: platforms aren't comparing accounts against some abstract template of a "normal advertiser." They're comparing each account's behavior against the behavior of other accounts that share its infrastructure. If that group already has a history of violations — or just exhibits atypical patterns — any new account entering the same environment starts getting associated with it automatically.
This doesn't mean warming up accounts has become pointless. It means the warm-up needs to happen inside infrastructure that doesn't create cluster links between accounts that are supposed to be independent from each other.
Operational Consequences That Usually Get Misdiagnosed
Teams running multiple accounts simultaneously run into several patterns that are genuinely difficult to interpret correctly without understanding cluster logic.
Simultaneous restrictions. Several accounts that had been performing fine individually suddenly show degraded results at the same time. The team starts looking for the cause in the creatives or in a platform algorithm update. What it actually means is that the platform started applying its scoring to the cluster rather than to individual profiles.
The contamination effect. One account that gets restricted or banned starts influencing the status of neighboring accounts in the same infrastructure environment. It doesn't happen immediately, and it's not always obvious when it does. But if the team doesn't isolate environments, the risk of restrictions spreading stays real.
Accelerated burnout. Accounts that operate in the same environment for too long start showing signs of accumulated cluster signal — even if they never technically violated any rules. The system simply begins treating them with reduced confidence as enough data accumulates about the connections between them.
None of this is a sudden catastrophe or a clean ban. It's a gradual degradation in operational quality that, in its early stages, is easy to write off as an algorithm change or a weak offer.
What Teams That Stay Stable Actually Do Differently
There's no single formula. But there are a few principles that consistently show up in teams that maintain launch quality while running multiple accounts in parallel.
First, isolation at the environment level, not just the IP level. Different accounts don't just run from different addresses — they run in environments that don't create shared behavioral traces. Separate devices or isolated profiles in an antidetect browser. Different subnets, ideally from real mobile carriers rather than different addresses within the same datacenter. Different activity patterns — across time, volume and interaction type.
Second, warm-up logic gets built with cluster context in mind. New accounts don't just go through a standard warm-up — they go through it in infrastructure that doesn't visually link them to other accounts on the same team. It takes more effort at the preparation stage, but it substantially reduces the contamination risk down the line.
Third, infrastructure rotation happens before a critical volume of signal accumulates, not after the first signs of restrictions appear. Most teams rotate reactively. A more stable approach treats regular rotation as part of the normal workflow rather than a response to problems.
This is exactly where proxy infrastructure quality starts affecting outcomes far more than most teams assume. The difference between a datacenter IP pool and a genuine mobile environment isn't just the type of address. It's a fundamentally different network profile — one that platforms have long since learned to distinguish statistically. AI-oriented mobile proxies like Proxies.sx are built on a proprietary modem farm and SDK-based real device network, without the reseller chains that inevitably create shared ASN traces across different clients. Daily IP rotation sourced from real carrier environments, combined with a pay-per-used-traffic billing model rather than time-based billing, makes this kind of infrastructure practically viable specifically for multi-account operations — where what matters isn't just address cleanliness, but the independence of network profiles between accounts.
Real Scenarios: What This Looks Like in Practice
Scenario one. A five-person team runs Meta Ads through a shared antidetect browser setup. Everyone manages their own accounts, everyone uses different proxies. But all sessions route through a single internal team server, and a set of environmental parameters is identical across all of them — the same browser version, the same extensions, nearly identical time zones. After several months of stable operation, moderation issues start appearing across multiple accounts simultaneously. The team concludes that the review algorithm changed. What actually happened is that the platform started seeing a cluster. Not by IP — by environment.
Scenario two. A team is running quality accounts, properly warmed up, with clean billing histories. One account gets restricted after an aggressive campaign launch. The team leaves it alone and keeps running the others. A few weeks later, problems start appearing on accounts that occasionally shared the same proxy network during warm-up with the restricted one. Not on all of them, not immediately — but the pattern is clear enough to notice. That's the contamination effect working through shared infrastructure history.
Scenario three. A team scales up, running dozens of campaigns in parallel. Everything works fine for several months. Then Google starts rejecting ads that had been passing without issue. Approvals slow down, sometimes with no clear explanation. The content is clean, the landing pages are fine. The issue turns out to be that several ad accounts running through the same rotation pool started forming a visible cluster trace through their temporal activity patterns. Google raised the review threshold for the whole group, even though nobody had technically violated anything.
None of these are edge cases. They're the common dynamics that teams hit once they've grown past the basic toolset but haven't yet rebuilt their infrastructure thinking.
FAQ
Can platforms actually see connections between accounts that never interacted directly?
Yes. Direct interaction is one of the weakest signals in the model. Behavioral similarity carries far more weight — how accounts operate, what environments they appear in, how closely their activity patterns resemble each other. That data accumulates regardless of whether there's any explicit link between the accounts.
Is rotating IP addresses enough to break cluster connections?
No, and this is one of the most common misconceptions. IP is just one parameter among many. Canvas fingerprint, behavioral patterns, temporal correlations, content overlap — all of this continues building a cluster profile even with complete address rotation.
How do you tell if a team has already fallen under cluster analysis versus a normal algorithm update?
Usually there are a few indicators: restrictions appear across multiple accounts simultaneously with no content-side explanation; problems start on new accounts immediately after they enter the same infrastructure; swapping proxies or changing devices doesn't improve the situation. It's not a precise diagnostic, but it's a consistent enough pattern.
Do mobile proxies actually help, or is that mostly marketing?
The difference is real, but it works only when the proxy infrastructure is built correctly. It's not about using mobile IPs as a fact — it's that genuine carrier environments with daily rotation produce a fundamentally different network profile compared to datacenter pools or overloaded rotation setups. Platforms see the difference because real mobile traffic behaves statistically differently from simulated equivalents.
Should a team fully isolate every account or is basic separation sufficient?
It depends on operational volume. At smaller scale, basic separation sometimes holds. Once you're scaling — it doesn't. The more accounts running simultaneously, the faster cluster signal tends to accumulate, usually faster than it seems.
How aggressively does TikTok apply cluster analysis compared to Meta and Google?
TikTok has been developing these mechanisms faster and more aggressively than most people anticipated. The platform is younger, but it has accumulated enough training data, and the responsiveness of its moderation system has grown noticeably over the past two years. In several verticals, TikTok's cluster analysis is now roughly comparable to Meta in terms of how tight it runs.
Instead of a Conclusion
Ad platforms didn't get smarter in some abstract sense. They simply accumulated enough data to see patterns where they previously saw only individual events. And that changes not just the technical side of multi-account operations — it changes the underlying logic of how infrastructure around campaign launches needs to be built.
Teams that keep thinking about accounts as isolated units will face growing instability as their volume increases. Not because they're doing anything fundamentally wrong — their infrastructure model has just become misaligned with how modern detection systems actually work.
Shifting to cluster thinking isn't about paranoid isolation of everything from everything else. It's about understanding that every infrastructure decision leaves a behavioral trace, and that trace gets read not just at the account level but across the entire group sharing a common environment.
The tools for this exist. AI-oriented mobile proxies built on real devices and genuine carrier environments are one of the infrastructure layers that addresses exactly the network side of the problem. Proxies.sx in this context works as an infrastructure layer for automated environments: support for HTTP/SOCKS5, REST API and MCP integrations allows it to be embedded directly into operational workflows without additional intermediaries.
But the tools aren't the main point. The main point is that platform-level evaluation shifted from the account layer to the cluster layer some time ago. Infrastructure logic needs to reflect that shift.